实时BI(三) 离线数据与实时数据处理的技术实现
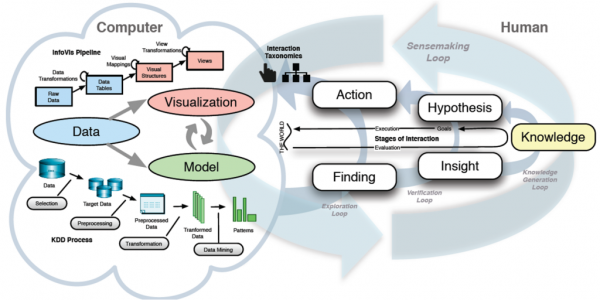
在实时商业智能(Real-time BI)的架构中,离线数据处理与实时数据处理是两大核心支柱,它们共同支撑着从海量数据中快速提取洞察的能力。本文将深入探讨这两种数据处理模式的技术实现路径,以及它们如何协同工作,为现代数据分析与处理提供强大动力。
1. 离线数据处理:批量计算的基石
离线数据处理,通常指对静态、大规模数据集进行批量计算和分析。其核心特征是处理周期较长(如小时、天或周级别),但能够执行复杂、深度的计算任务。
技术实现要点:
- 存储层: 主要依赖于分布式文件系统(如HDFS)或对象存储(如AWS S3),用于存放原始日志、事务记录等历史数据。
- 计算引擎: 以Apache Hadoop MapReduce、Apache Spark(批处理模式)为代表。Spark凭借其内存计算和DAG执行引擎,在迭代计算和复杂ETL任务上性能显著。
- 调度与管理: 使用Apache Airflow、Oozie等工作流调度工具,实现依赖管理、定时触发与监控。
- 数据仓库: 经过清洗、转换后的数据被加载到数据仓库(如Hive、ClickHouse)或数据湖中,供后续的离线报表、即席查询使用。
离线处理的优势在于其强大的吞吐量和处理深度,适合构建企业级的“单一事实来源”,为战略决策提供历史趋势分析和宏观视角。
2. 实时数据处理:即时洞察的引擎
实时数据处理则关注对持续不断产生的数据流进行即时处理,力求在毫秒到秒级内完成计算并输出结果,以支持实时监控、预警和个性化推荐等场景。
技术实现要点:
- 数据采集与接入: 通过消息队列(如Apache Kafka、Pulsar)作为数据流的“中枢神经系统”,以高吞吐、低延迟的方式接收来自应用日志、IoT设备等的实时事件。
- 流计算引擎: 这是实时处理的核心。Apache Flink因其真正的流式处理架构(低延迟、高容错)、精确一次(exactly-once)语义和丰富的状态管理而成为主流选择。Apache Storm和Spark Streaming也各有其应用场景。
- 实时计算模式: 主要包括窗口计算(如滚动窗口、滑动窗口)、流式聚合、复杂事件处理(CEP)以及流批一体(如Flink Table API/SQL)等。
- 结果输出: 处理后的实时指标或事件可实时写入OLAP数据库(如Druid、ClickHouse)、键值存储(如Redis)或直接推送至前端仪表板,实现秒级可视化。
实时处理的价值在于其时效性,它让企业能够对正在发生的业务动态做出快速反应,优化运营效率与用户体验。
3. 离线与实时的协同:Lambda与Kappa架构
在实际系统中,离线与实时处理并非割裂,而是通过特定架构模式协同互补。
- Lambda架构: 这是经典的混合架构。数据流同时进入批处理层(离线)和速度层(实时)。批处理层提供准确、全面的历史视图;速度层提供近实时的最新视图。服务层将两者结果合并后提供给应用。其优点是兼顾准确性与时效性,但缺点是需要维护两套逻辑不同的代码库,系统复杂性高。
- Kappa架构: 作为Lambda架构的简化,它主张只保留流处理层。所有数据,无论历史还是实时,都通过消息队列接入,并由同一套流处理引擎(如Flink)处理。对于历史数据的重新计算,通过从头消费持久化的消息日志来实现。Kappa架构统一了技术栈,降低了运维复杂度,但对消息队列的存储能力和流处理引擎的回放计算能力要求更高。
随着Flink等流批一体引擎的成熟,一种新的趋势是流批融合。开发者可以用同一套API(如SQL)来描述处理逻辑,引擎根据数据源特性(有限数据集/无界数据流)自动选择执行模式,从根本上简化了架构。
4. 技术选型与未来展望
选择离线、实时还是混合架构,取决于具体的业务需求、数据特性(速度、体量、多样性)以及对数据一致性、延迟和准确性的要求。
- 离线处理仍是数据仓库建设、训练机器学习模型和生成深度分析报告的基础。
- 实时处理则是数字化转型中实现敏捷运营、实时风控和智能交互的关键。
数据处理技术的发展将继续朝着统一化、实时化和智能化迈进。流批一体的计算引擎将逐渐成为标准,云原生与Serverless架构将进一步提升资源弹性与运维效率,而AI与数据处理的深度融合(如实时特征计算、流式模型推理)将催生出更加智能的实时BI应用,让数据驱动的决策真正变得无处不在、无时不在。
如若转载,请注明出处:http://www.iata-boms.com/product/53.html
更新时间:2026-02-28 21:04:07